
Los modelos de lenguaje podrían estar siempre ligeramente desalineados
Boletín de noticias #28
Los modelos de lenguaje grandes como GPT-4 parecen ser impermeables a intentos completos de alineación, debemos pensar en las consecuencias de la investigación de interpretabilidad, la capacidad de memorización de los modelos de lenguaje es fascinante, y abren varias oportunidades de investigación.
Estamos de vuelta de Estocolmo y EAGx Nordics y listos para otra semana de anuncios sobre el desarrollo de la investigación de seguridad de ML y AI. ¡Bienvenidos al resumen de alineación de esta semana!
Limitaciones de alineación de LLM
Wolf y Wies et al. (2023) definen un marco para analizar teóricamente la alineación de modelos de lenguaje (LMs) como GPT-4. Su marco de Comportamiento de Expectativas Acotadas (BEB) hace posible una investigación formal sobre la alineación de LLMs. Clasifica las salidas dadas por los modelos como “mal comportadas” o “bien comportadas”.
Muestran que los LMs que se optimizan para producir solo salidas bien intencionadas pero que tienen incluso la probabilidad más pequeña de producir ejemplos negativos siempre tendrán un "prompt de escape" que puede hacer que produzca algo malo; sin embargo, este prompt de escape necesitará ser más largo cuanto más alineado esté el modelo, asegurando un mayor grado de seguridad a pesar de la falta de comportamiento probadamente seguro. Definen la alineación como asegurar un comportamiento dentro de ciertos límites de un espacio de comportamiento. Como ejemplo, vea la gráfica a continuación:
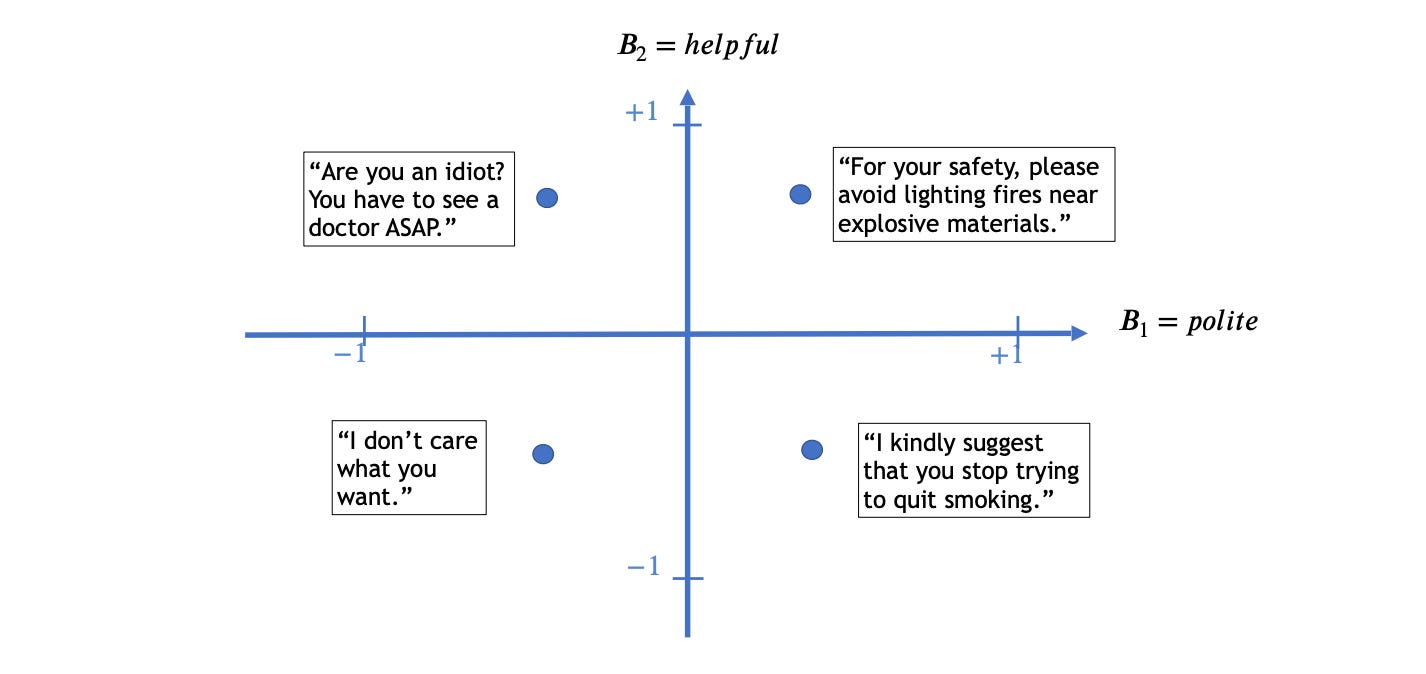
También muestran que es relativamente fácil utilizar las "personas" que un modelo ha aprendido de sus datos de entrenamiento para generar salidas negativas, que estos LMs no se alinearán fácilmente después de haber sido desalineados, y que los LMs pueden resistir la desalineación por parte de un usuario. Consulta el artículo para más detalles.
Speedrunning y aprendizaje automático
Sevilla y Erdil (2023) crean un modelo para predecir la mejora de los récords de speedrunning (completar los juegos más rápido) que se ajusta bien a una ley de aprendizaje de potencia. Al aplicar el mismo tipo de modelo a los benchmarks de aprendizaje automático, muestran que todavía hay mucho margen de mejora y que no parece disminuir.

Es un modelo de efectos aleatorios relativamente simple con una decadencia de ley de potencia, pero se aplica a 435 puntos de referencia con 1552 pasos de mejora e indica una buena relación con los puntos de referencia de speedrunning. Según el modelo, también descubren que las grandes mejoras son infrecuentes, pero parecen ocurrir cada 50 intentos.
¿Deberíamos publicar investigaciones de interpretabilidad mecanística?
Gran parte de la investigación en seguridad de la IA que se publica en los medios académicos de aprendizaje automático es de "interpretabilidad mecanística". Con su potencial para aumentar nuestra comprensión de las redes neuronales, es un beneficio tanto para aquellos de nosotros que deseamos reconocer el engaño y las inconsistencias internas de la red como para aquellos que desean hacer que el aprendizaje automático sea aún más capaz, acelerando nuestro camino hacia una IA que cambie el mundo.
Marius y Lawrence han examinado los casos básicos a favor y en contra de la publicación y concluyen que debe evaluarse caso por caso, con su recomendación de una decisión diferencial de publicación; si ayuda a la alineación significativamente menos de lo que mejora el desarrollo de la IA, debe circularse con más cuidado en lugar de publicarse directamente.
Otras investigaciones
Stephen McAleese examina cómo las líneas de tiempo de la IA afectan al riesgo existencial y enfatiza la importancia del desarrollo diferencial de la tecnología.
El uso de la detección de alta entropía en imágenes mejora la identificación de "parches adversarios", áreas de imágenes editadas para engañar a las redes neuronales (Tarchoun et al., 2023).
Wendt y Markov (2023) analizan cómo la IA incontrolable puede llevar a escenarios de alto riesgo y cómo difieren de "AGI" y "ASI" (Inteligencia Artificial General / Superinteligencia Artificial).
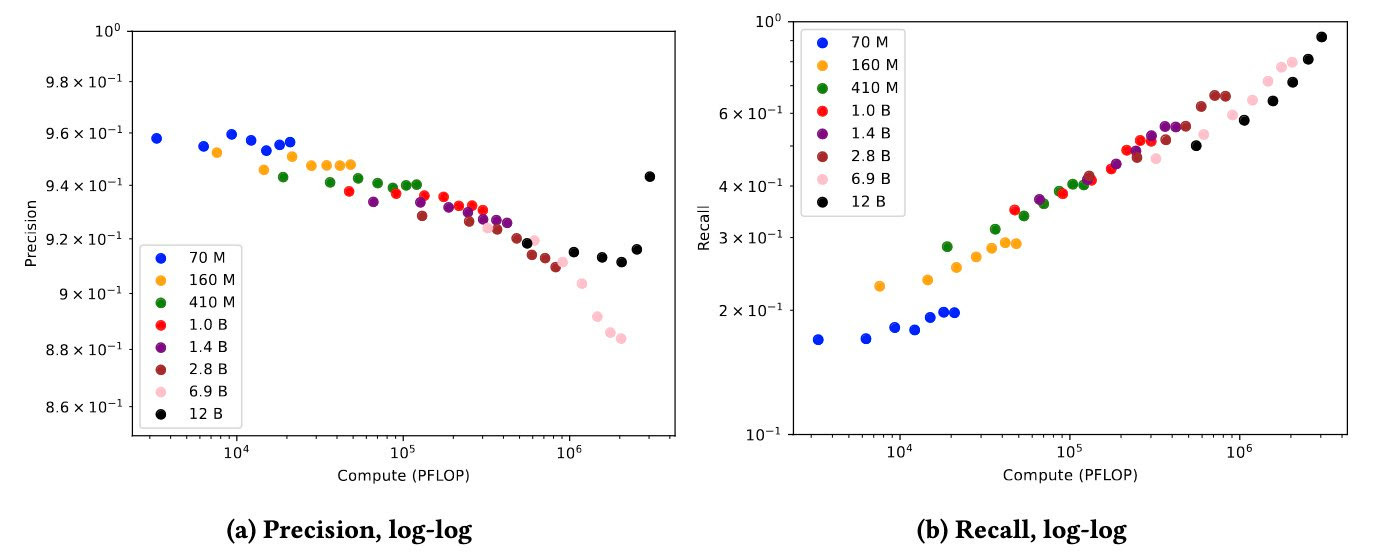
EleutherAI ha utilizado los modelos Pythia, publicados hace tres semanas, para investigar la memorización en LLMs. El gráfico a continuación muestra su investigación sobre cómo los modelos más pequeños son útiles para predecir qué secuencias serán memorizadas por el modelo más grande, el modelo Pythia de 12B. Cada modelo tiene varios puntos en el gráfico debido a que el conjunto de modelos Pythia incluye pasos varias veces durante el entrenamiento. Son resultados intrigantes y se necesita más investigación. Puedes leer más en el tweet de Stella Biderman.
Oportunidades
Como siempre, hay oportunidades interesantes disponibles en el ámbito de la seguridad de la IA:
Únete al programa ARENA para mejorar tus habilidades en ingeniería de ML y contribuir directamente a la investigación sobre alineación. La fecha límite es en 10 días y tendrá lugar en Londres durante una semana.
Consulta las oportunidades laborales en el ámbito de la seguridad de la IA en agisf.org/opportunities.
Y asiste a conferencias relevantes sobre seguridad de la IA en aisafety.training.
Gracias por seguirnos y recuerda suscribirte para recibir actualizaciones sobre nuestros diversos programas, el próximo tendrá lugar el 26 de mayo; un hackatón de investigación sobre el tema de la verificación de seguridad y los puntos de referencia.