
Boletín Semanal # 27
Investigación sobre seguridad ML en interpretabilidad y modelos compartidos, modelos lingüísticos de juego y críticas a la investigación sobre riesgos AGI.
Esta semana echamos un vistazo a las nuevas exploraciones del espacio de características, modelos para analizar la dinámica de entrenamiento y reflexiones sobre el espacio de riesgo de la IA. También compartimos algunos boletines colegas que se están iniciando en la seguridad de la IA junto con interesantes oportunidades dentro de la seguridad de la IA.
Investigación en seguridad ML
Pythia (Biderman et al., 2023) es un conjunto de datos de 8 modelos entrenados con parámetros que oscilan entre 19 millones y 12.000 millones. Estos modelos se entrenan para abrir nuestra capacidad de investigar cómo aprenden los grandes modelos y dan acceso a copias del modelo guardadas durante el entrenamiento. Comprender cómo aprenden los "cerebros de IA" es importante para encontrar nuevas vías de alineación.

Un nuevo artículo de Redwood Research presenta trabajos para localizar comportamientos de redes neuronales en partes de su estructura interna (Goldowsky-Dill et al., 2023). Formalizan el parcheo de trayectorias y lo utilizan para probar y refinar hipótesis de comportamientos en GPT-2 y más. Puedes explorar su herramienta de búsqueda de modelos de comportamiento.
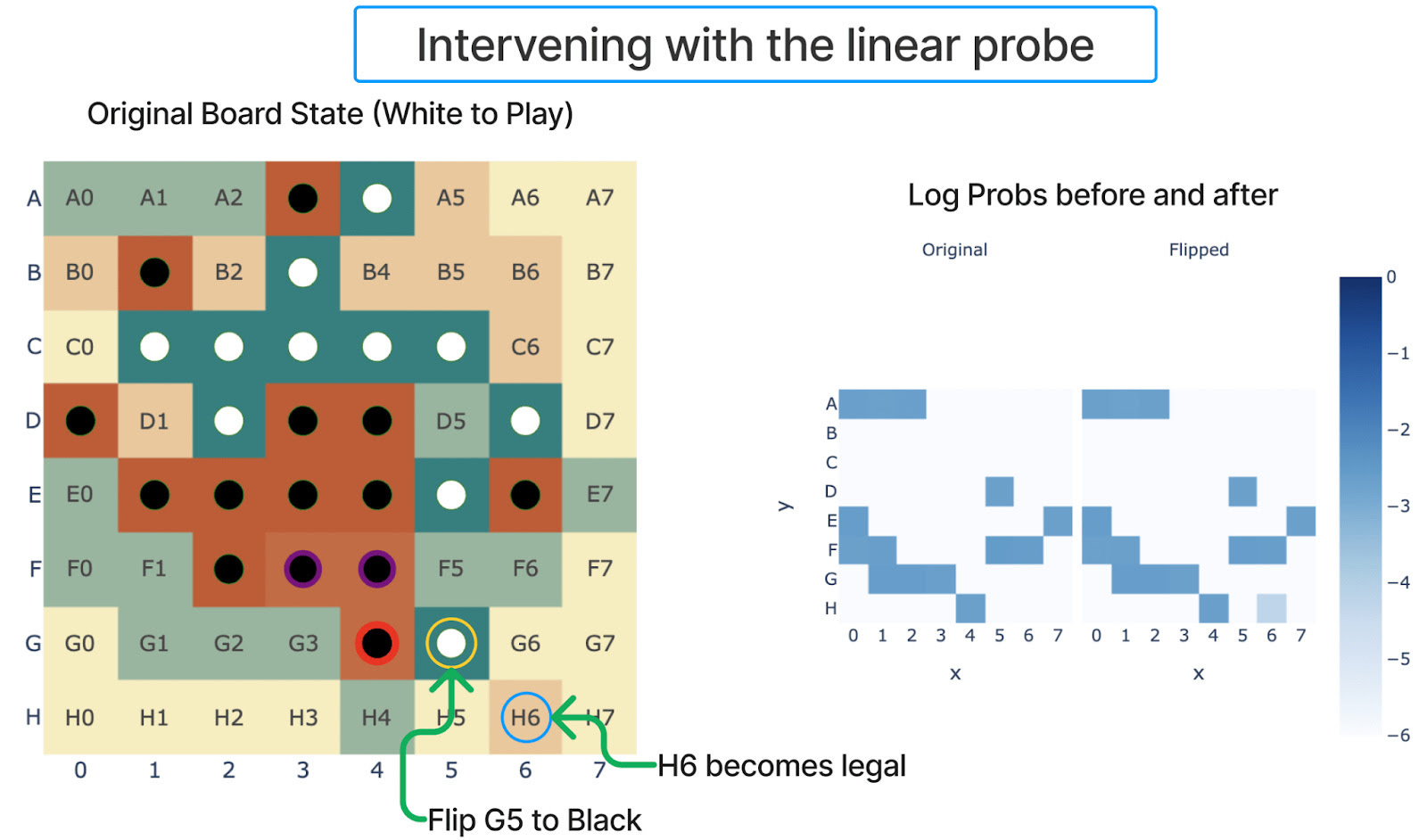
En un trabajo reciente, Neel Nanda se basa en la investigación sobre Othello-GPT (Li et al., 2023) que se entrena para realizar movimientos legales aleatorios en el juego de mesa Othello. Una teoría común es que las características de la comprensión de una red se codifican linealmente y Li et al. demuestran que no es el caso de la representación neuronal del estado del tablero.
Esto estaba a punto de dar la vuelta a nuestra comprensión de las características; sin embargo, Nanda (2023) muestra que si reinterpretamos las características, podemos extraerlas usando un tipo de "regresión logística" sobre la activación neuronal. Con una simple transformación, la interpretabilidad afortunadamente sigue siendo linealmente interpretable.
Neel Nanda también se unió a nosotros para que el hackathón de interpretabilidad 2.0 fuera un éxito este fin de semana. Podrás seguir las presentaciones de los proyectos el próximo martes, pero a modo de breve resumen, los equipos trabajaron para:
Identificar puntos de inflexión en el aprendizaje del modelo (enlace).
Desarrollar una forma de inspeccionar cualitativamente muchas neuronas de la red Othello-GPT (enlace a la herramienta y al informe).
Mejorar la biblioteca TransformerLens (enlace al informe y TransformerLens)
Investigar cómo el abandono afecta a las bases privilegiadas (enlace)
Y más...
Reflexiones sobre la investigación del riesgo de IA
Jan Kulveit y Rose Hadshar describen cómo las propuestas habituales de alineación ignoran que el sistema con el que intentamos alinearnos (los humanos) no suele estar alineado en sí mismo. Esto hace que varios tipos de propuestas se tambaleen.
También ofrecen una visión general de las formas de resolver este problema, con ejemplos como alinearse con Microsoft en lugar de con los humanos, tener en cuenta nuestras preferencias sobre nuestras preferencias y utilizar los mercados.
David Thorstad critica algunas de las estimaciones de riesgo extremo sobre la IA desde el principio de que varias partes de los cálculos de riesgo no tienen datos ni argumentos significativos detrás. Esto se hace eco de críticas anteriores de Nuno Sempere y Ben Garfinkel, que destacan respectivamente cuestiones de estimación y de deferencia.
Se ha publicado un post anónimo en el que se critica a uno de los mayores laboratorios sin ánimo de lucro dedicados a la seguridad de la IA, en el que se describen problemas relacionados con la experiencia de los investigadores y los conflictos de intereses con sus subvencionadores.
Steven Kaas invita a la gente a hacer preguntas sobre la seguridad de la inteligencia general artificial (AGI). Ya tiene más de 100 comentarios y podría ser interesante explorarla. Por ejemplo, "¿en qué medida supone un riesgo la AGI?" y "¿es siquiera posible la alineación?".
¿Y qué más?
Ha salido un boletín sobre la gobernanza de la IA y la navegación por los riesgos de la IA durante el próximo siglo. Se centra en cómo podemos gobernar los riesgos planteados por la inteligencia artificial transformadora y recibirás sus reflexiones en extenso sobre cuestiones fundamentales en la gobernanza de la IA junto con una visión general de lo que ha estado sucediendo cada 2 semanas.
Nonlinear ha puesto en marcha una red de financiación para la seguridad de la IA con más de 30 donantes privados e invita a enviar solicitudes de subvención antes del 17 de mayo.
El Center for AI Safety ha lanzado un boletín informativo sobre lo que está ocurriendo en la seguridad de la IA con su primer post de hace una semana. Ya comparten mensualmente el ML Safety Newsletter, en el que exploran temas de investigación sobre seguridad en ML.
Oportunidades en seguridad ML
Como de costumbre, damos las gracias a nuestros amigos de aisafety.training y agisf.org/opportunities por trazar un mapa de las oportunidades disponibles en la seguridad con IA. Consúltelos aquí:
Envíe sus perspectivas y exploraciones de nuestras expectativas sobre cómo se desarrollará la IA con el Premio Open Philanthropy's Worldview. ¡Puedes ganar hasta 50.000 dólares!
El 21 de abril se abren las inscripciones para la beca de política tecnológica y de seguridad de la RAND Corporation para llevar a cabo una investigación independiente sobre la gobernanza de la IA.
Solicita antes del 30 de abril un puesto de becario en el Krueger Lab. Trabajan en la investigación de la seguridad ML y están realizando una gran labor dentro de la divulgación académica.
El mismo plazo se aplica para participar en la conferencia Effective Altruism Global (EAG) de Londres que tendrá lugar el mes que viene. Inscríbete aquí.
Gracias por seguirnos y no olvides compartir esto con tus amigos interesados en la investigación de la alineación. Puedes seguir tanto este boletín como las actualizaciones de nuestro hackathón en news.apartresearch.com.
Gracias por leer el boletín de Apart. Suscríbete gratis para recibir nuevos posts y apoyar nuestro trabajo.